
新闻中心
NEWS CENTER
16
2026-03
ByteMLPerf 实测:天数智芯 GPGPU 全链路技术解析,创新释放高效算力
ByteMLPerf是开源的AI加速器基准测试套件,专注于从用户和实际生产角度评估AI芯片的性能,涵盖易用性、灵活性及能效比等维度。近日,基于ByteMLPerf对天数智芯GPGPU芯片开展系统评测,通过分阶段测试芯片在指令、算子、模型等多个维度的性能表现,助力读者更深入地了解该芯片的架构、性能表现及使用方法。
测试结果显示,天数智芯在实测场景下的GEMM算子、FA算子均能达到较高效率,充分释放了硬件能力。在大模型应用上,该款芯片通过巧妙的并行策略,扬长避短,实现了很好的性能表现。同时,天数智芯SIMT架构带来的高通用性、灵活性,也为未来大模型结构的变化等做了充足的准备,降低了开发者的学习成本和使用难度。
感谢ByteMLPerf开源框架提供的标准化评测基准。借助这一框架,天数芯片的性能特点与优化方向得以清晰呈现,也助力天数智芯更精准地提升芯片在实际应用中的价值。
以下为ByteMLPerf测试报告摘要:
天数智芯测评技术报告
构建开源AI硬件评测工具,ByteMLperf-v1.0 X 天数智芯,扬长避短是关键
1. 引言-评估方法论
计算机系统评估与性能分析旨在运用测量、模拟等手段及工具,获取计算机执行任务时的性能特征,识别性能瓶颈,从而达成计算机系统的评估。本博客计划依据此方法论对一款天数智芯GPGPU芯片(以下简称“天数芯片”)开展系统评测,通过分阶段测试芯片在指令、算子、模型等多个维度的性能表现,助力读者更深入地了解该芯片的架构、性能表现及使用方法,探寻更为高效的架构与使用方式。
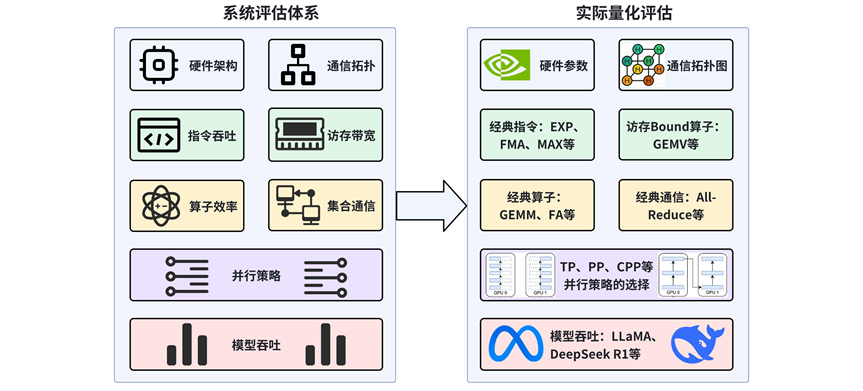
本博客将对硬件能力与软件优化这两大方向展开系统化评估。硬件能力层面涵盖单芯片硬件架构(如计算架构、存储层次架构、片内互连架构等)以及多芯片互联架构(包括硬件组件间的通信拓扑、通信接口、通信协议等)。软件优化层面包含图优化、算子优化、指令编译优化等多维度的优化手段。整体评估性能指标包括指令吞吐与延迟、访存吞吐与延迟、算子效率以及集合通信吞吐与延迟等,旨在量化硬件在不同计算和通信任务中的表现。
具体而言,本博客将呈现实际量化评估的流程:首先,从理论和分析层面对比硬件参数(算力、内存容量、互连带宽),并分析通信拓扑;其次,在单芯片层面测试经典指令与算子(如计算密集型、访存密集型、通信密集型等);最后,在多芯片层面先选取合适的并行策略(如张量并行(TP)、流水线并行(PP)),并在实际模型(LLaMA、DeepSeek R1)上验证吞吐量,以此综合评估硬件性能和优化策略的成效。
2. 硬件架构分析
2.1 架构参数分析
天数智芯GPGPU芯片属于通用GPU架构类型,用于通用计算和AI加速。在计算单元个数上,天数芯片的多流处理器数量较A800略少,支持的数据类型包括FP32、FP16、INT8 等,其中软件层面上支持了FP8和FP4。在卡间互联方面,天数芯片使用 PCIe-Switch进行卡间互联,可实现多卡级联,在一定程度上满足中等规模的联合工作需求。其互联策略更适合通信相对较轻的任务类型,如模型推理阶段的并行计算或局部计算密集型场景。在缓存与片上存储结构上,天数芯片提供多级缓存体系,包括L1、L2 和共享内存,但结构细节与A800有所不同,可减少一定程度的数据访问延迟,为密集型算子提供较好的局部数据复用能力。
2.2 GPGPU架构分析与对比
天数芯片和英伟达A800 80GB SXM采用相似的GPGPU架构,兼容了GPU Processing Cluster、Texture Processing Cluster、Streaming Multiprocessor、Tensor Core和Cuda Core等概念。计算层次为GPC-TPC-SM-Cuda/Tensor Core,天数芯片单个芯片包含4个GPU Processing Cluster (GPC),每个GPCs包含4个Texture Processing Cluster(TPC),每个TPC包含4个Streaming Multiprocessor(SM),每个SM都有相应的张量核心/矢量核心。芯片的内存层次由外部显存、片上二级缓存以及一级缓存/共享存储构成,L2和L1/shared memory之间以Crossbar的方式连接,每4个SM共享一个L1/shared memory以节省L2-L1/shared memory的布线资源。
与英伟达A800对比而言,A800有8个GPCs, 每个GPCs有8个TPCs,每个TPCs 有2个SMs,整个芯片有128个SMs (也有版本108SMs)。
从内存层次架构看, 天数芯片有64GB 外部显存,16MB L2 cache,192KB L1 cache/shared memory。在 A800 对应的架构中,每个NV SM独享一个192KB L1存储。天数的优势是4个SM 共享一个L1, 进行数据共享,减少对L2的带宽需求,进而降低布线需求。

天数芯片硬件架构

英伟达A800芯片硬件架构[参考白皮书]
2.3 单SM硬件架构分析与对比
以下第一张图片展示了天数芯片单个流式多处理器(SM)的硬件架构,第二张图片呈现了英伟达A800 GPU的SM硬件架构。二者的相同点在于,这两款芯片的SM中张量核心(兼容Tensor Core)与矢量核心(兼容cuda core,包含特殊函数单元SFU)是分离的,可并行执行任务,且能实现数据共享,这对挖掘数据复用性十分有益。
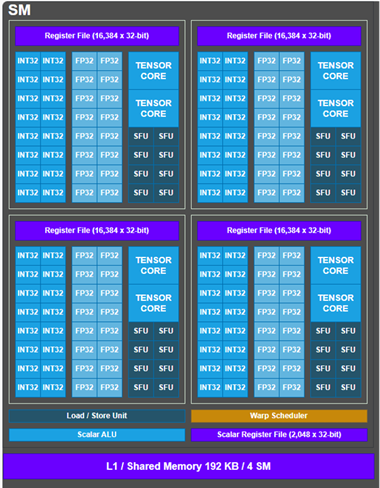
天数智芯单个SM的硬件架构
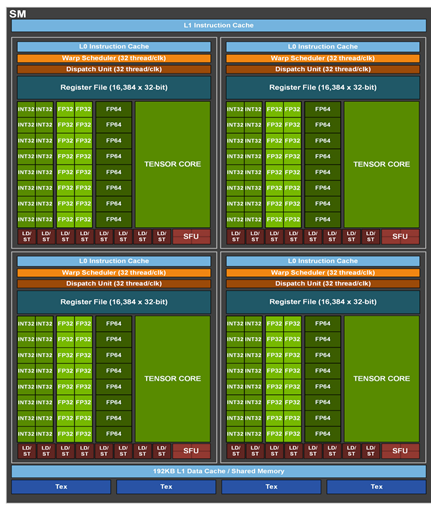
英伟达A800单个SM的硬件架构[参考白皮书]
在调度层面,天数智芯借助一个调度器和一个标量算术逻辑单元(Scalar ALU),完成了单个SM内4个核心的计算调度。而A800则采用4个线程束调度器(Warp Scheduler)来实现单个SM内4个核心的调度。从这些设计选择来看,A800的调度方式更为灵活,而天数智芯的芯片则更节省用于调度器的芯片面积。
2.4 架构亮点
天数芯片的架构设计具备以下架构优势:
- 采用 GPGPU 架构,且在设计时考虑CUDA兼容,因此可以高效支持CUDA框架以及相关生态,可快速适配人工智能领域的新模型,在AI等领域具有较强的适应性。
- 缓存复用效率较高。通过精妙的硬件分层设计,达成了类似于 H100 上 DSM 的高效共享内存,且访问延迟显著低于 H100。因此,天数芯片能够以更低的功耗和更小的面积提供更大的算力。
- 调度支持度高,支持通信与计算流程的高度自定义,对通信计算融合、算子融合以及不同内核的灵活调度等方面的支持良好,易于通过软件优化实现硬件利用率的最大化。
- 相较于 A800,SME Engine(一种异步DMA引擎) 和Scalar Unit 等设计可在更低能耗下实现更高的计算及访存效率,并且在硬件层面能够高效支持非 k - major 的 int8 格式矩阵运算。
3. 软件优化分析
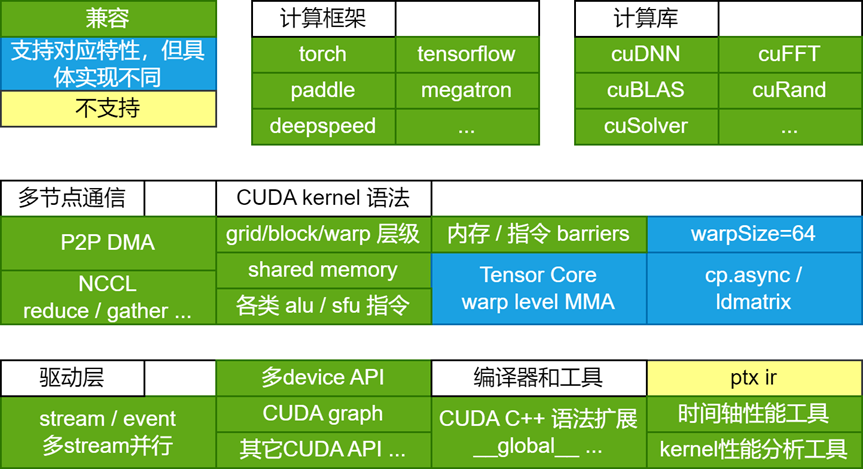
3.1 类CUDA编程生态
天数芯片采用和CUDA一致的异步编程模型,在CUDA/C++语法、计算网络划分(grid,block,warp)以及计算流控制(stream)等方面都提供了高度兼容的开发体验,同时通过优秀的软硬件协同能力,达到对底层硬件资源的细粒度控制,最大化利用每一份计算资源。
以计算流为例:软件上,支持兼容CUDA stream形式的launch -> execute -> wait异步流程;硬件上,天数芯片有多个流式调度单元,能够根据任务属性,动态分发不同流的计算block和通信任务。用户可通过多流的控制实现SM效率以及计算/通信能力的最大化。天数芯片也支持兼容CUDA Graph等特性,对于需要低延迟、高吞吐量的推理场景,能够大幅提升调度效率。
3.2 会用才是关键
虽然A800的纸面数据略胜一筹,但实践是检验真理的唯一标准,两者实际性能表现如何,必须放在具体的场景中来对比,而其中会用才是关键。在天数芯片上调优GEMM/FA等算子的过程中,由于天数拥有从算子库到编译器完整的软件栈,以及硬件RTL仿真环境,所以可以在每一处细节上进行极致调优。
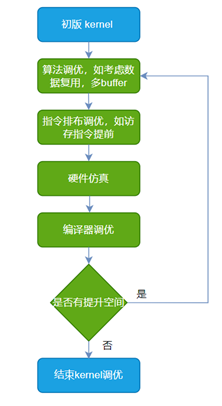
例如在进行FA算子调优时,先在算法层面做好分块策略以及数据复用之类的工作,再通过分析指令流以评估编译器是否有调优空间,最后通过实测以及硬件仿真得出实际的性能。而仿真波形可以帮助分析硬件Matrix、Vector以及LSU单元的效率,这个结果可以反馈给算子或编译器,通过继续调优以提高硬件各功能单元的效率,将硬件性能压榨到极致。而在A800上调优算子的过程中,由于缺乏硬件RTL仿真环境,无法利用仿真波形来指导算子和编译器,所以想要达到如天数芯片这样清楚每一处细节,是完全做不到的。在天数芯片上极致调优kernel流程如下图所示,MFU使用case QKV BF16, batch=8, head_num=8, seqlen=1024, head_dim=128, causal=false 测得。
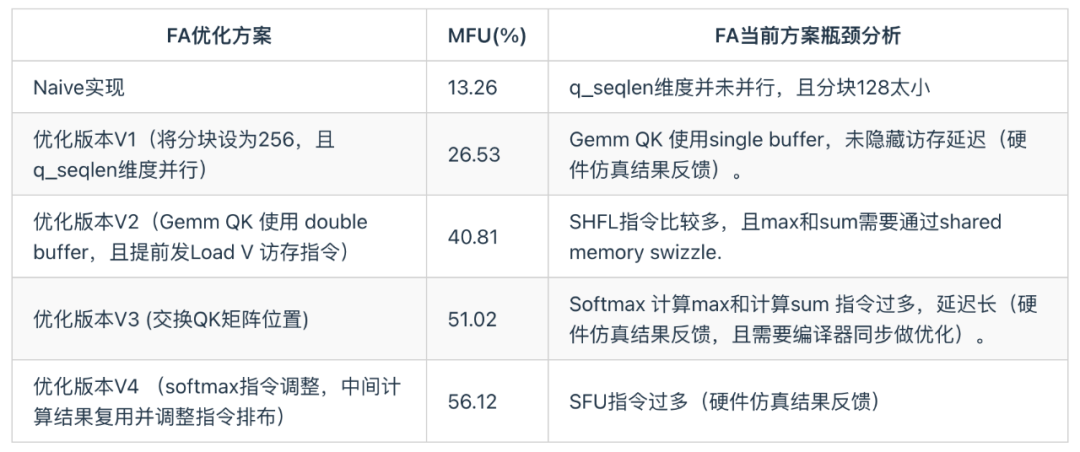
下面具体对大模型中最关键算子FlashAttention(FA)进行分析。
- 天数充足的向量算力能够确保 FA 算子在该款芯片上不会受限于向量算力,这有利于提高矩阵单元的利用率。
- 其次,由于 FA 算子包含大量的 exp 计算,所以 SFU 的算力对于 FA 性能至关重要。天数芯片具备强大的 SFU 算力。
而以上只是在算子调优过程中体现出来的“会用”,除此之外,在进行系统调优时,“会用”更加关键。天数芯片采用PCIE Switch,互联带宽逊色于A800 SXM。在调优大模型多卡推理时,由于涉及复杂的通信和计算,如何让通信和计算overlap起来,提高计算吞吐的同时隐藏通信的延迟变得尤为关键。而天数做到了通算深度融合,卡间通信完全被计算所掩盖。这块内容后文会详细解释。
3.3 指令吞吐
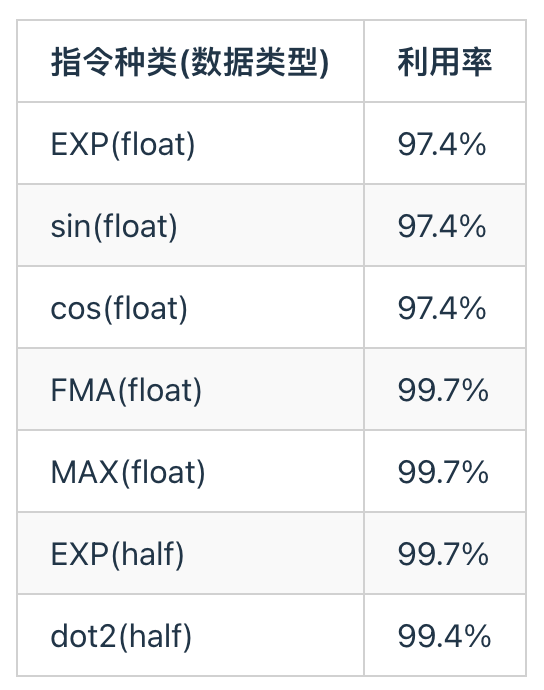
天数芯片的矢量核心计算单元是由BFU(Basic Function Unit)和SFU(Special Function Unit)组成,其中BFU支持INT32/FP32的计算,SFU为特殊函数计算单元,用于sin/cos/log/exp/sqrt/rsq/ecp等计算指令。同时由于天数芯片采用和兼容CUDA的异步编程模型,只需要掌握基础cuda编程技术即可将矢量核心计算单元的算力发挥到理论峰值的95%以上。
在ByteMLPerf中的byte_micro_perf中,我们提供了测试程序和kernel程序,测试数据和伪代码如下所示。通过运行测试程序可以测算出在FP32数据格式下,BFU和SFU的实际算力为接近100%的算力利用率。由于vector单元的利用率高以及vector和tensor core单元可以并行执行,在大模型训练推理中,天数这款芯片可以很好地将SFU计算隐藏在Tensor core计算中,提高计算效率。
伪代码如下:

3.4 访存带宽
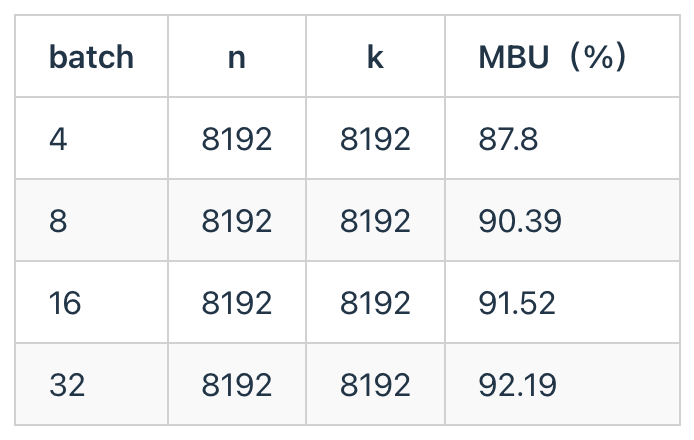
为了测试天数芯片的实际访存带宽利用率,我们使用了LLM decode过程中的典型内存瓶颈算子GEMV并考虑了AWQ量化方法。具体而言,AWQ量化的权重是uint4,激活是fp16,scale groupsize是128。GEMV是decode阶段的算子,即矩阵乘向量,由于序列长度较小,所以一般是内存瓶颈。用AWQ GEMV来测试MBU,实测数据如下:
伪代码如下:
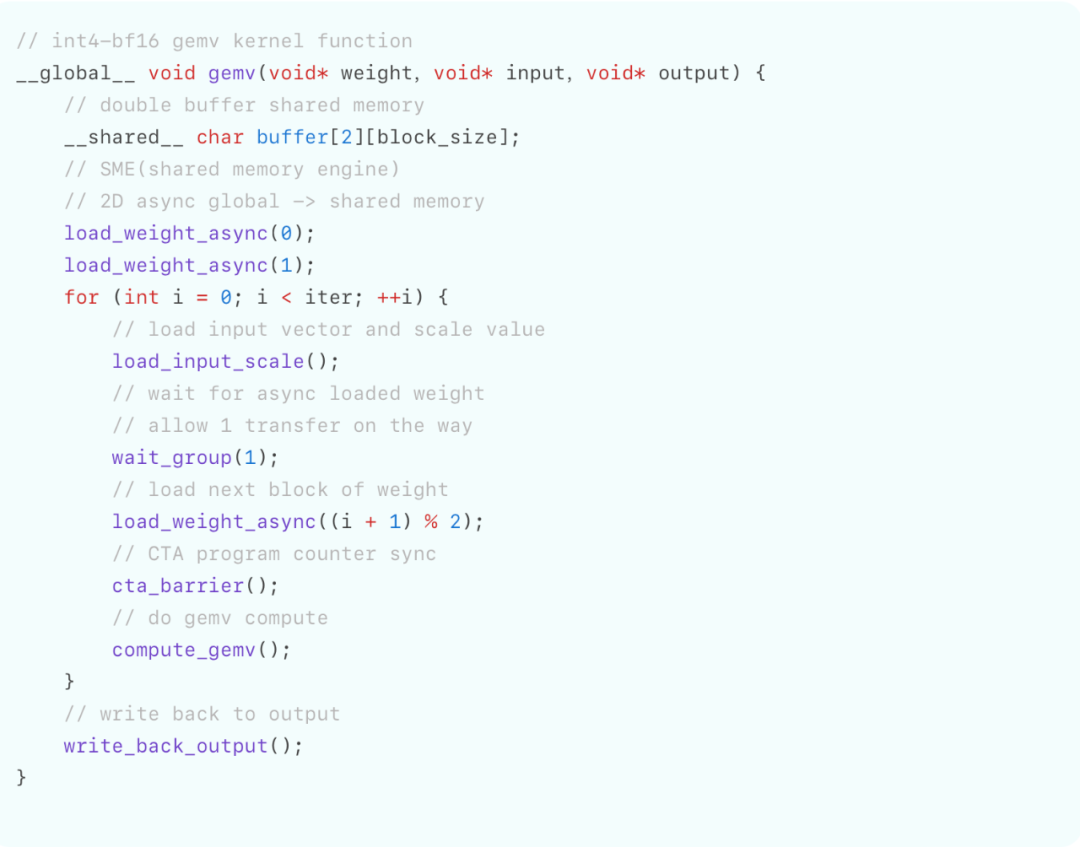
得益于先进的异步SME Engine设计,较为灵活的架构和较高的vector算力,天数芯片在AWQ GEMV中能达到超过90%的带宽利用率。
3.5 GEMM算子实测分析
基于ByteMLPerf 中几种常用的矩阵规模,对 INT8 GEMM 算子进行了评估,并测量了天数芯片与 A800 在这些shape下所能达到的算力利用率。
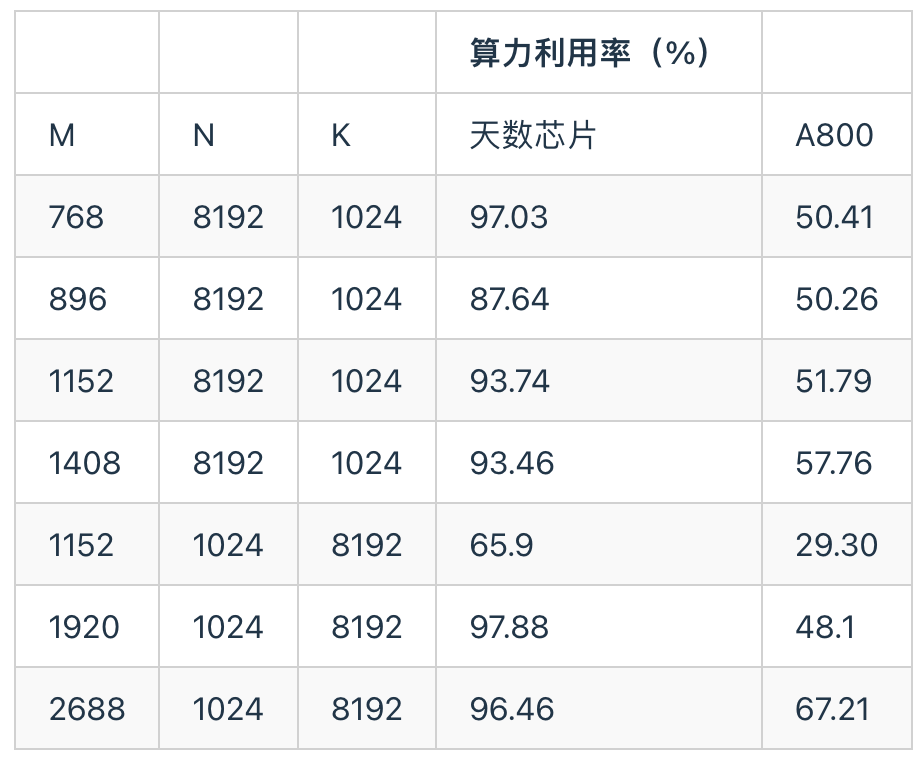
从结果可以看到,在多种典型规模下,天数芯片能够维持较高的算力利用率,特别是在大尺寸矩阵计算中,其计算阵列能够得到充分发挥,表现出较强的硬件效率稳定性。
3.6 FA算子实测分析
3.6.1 纯BF16类型MFU对比
我们将针对天数芯片和英伟达 A800 的 FA 算子的纯 BF16 类型 MFU 进行对比。如下表所示,q_head_dim等于kv_head_dim,横坐标表示输入序列的长度,纵坐标表示 MFU。
A800 FA测试使用的是目前最常用的Dao-AILab开源flash-attention实现,版本为Release v2.7.4。 天数芯片FA测试使用ByteMLPerf框架。
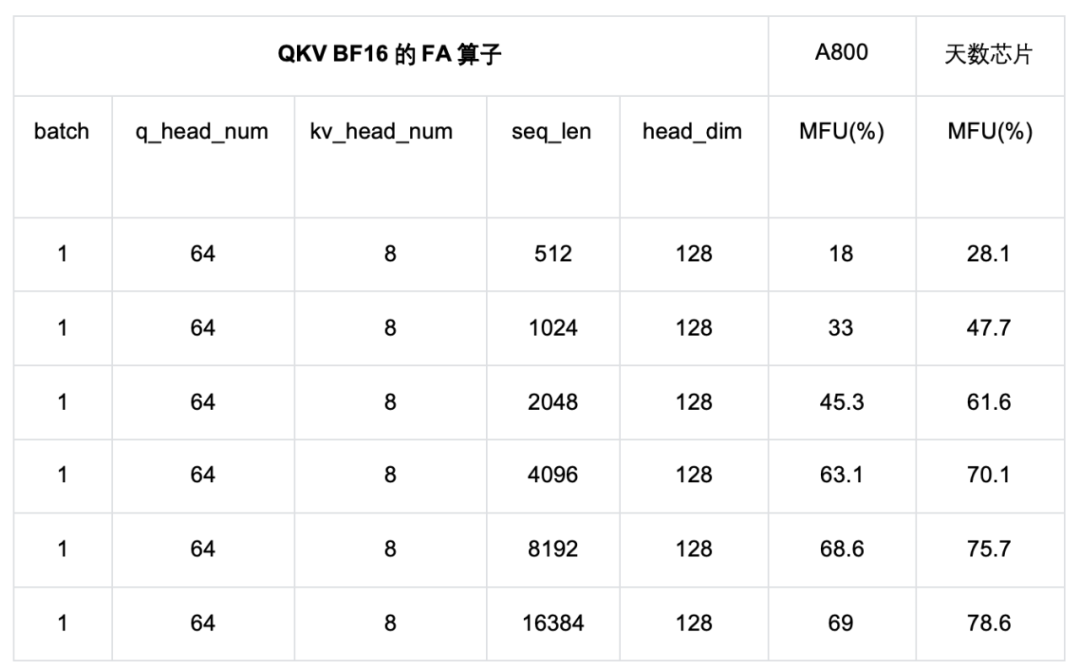
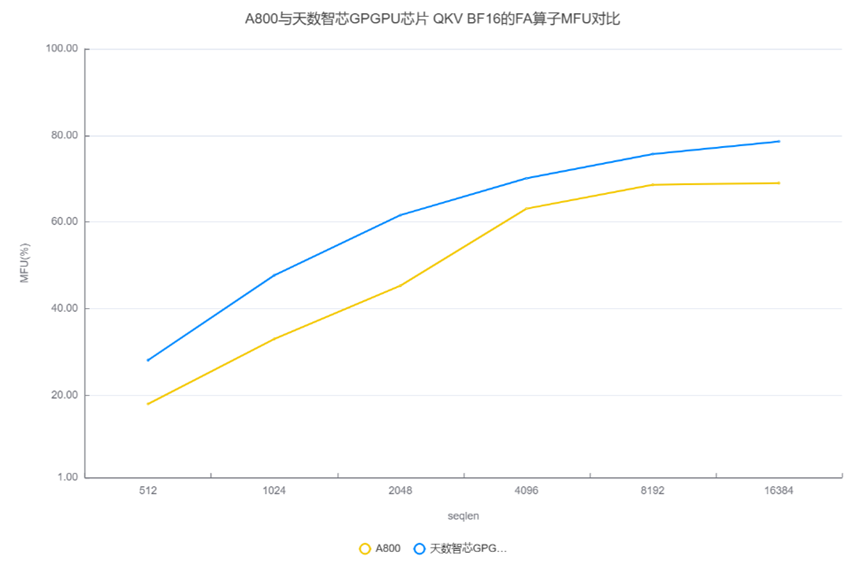
如上图所示,从QKV BF16 的性能测试结果来看,无论在短seqlen还是长seqlen上,天数芯片相较A800都表现出更高的MFU,这展现出了天数GPGPU极高的FA效率,充分体现了天数GPGPU架构的高效性。
3.6.2 INT8类型MFU对比
下表是天数芯片 QKV Int8 类型的 FA 测试结果。
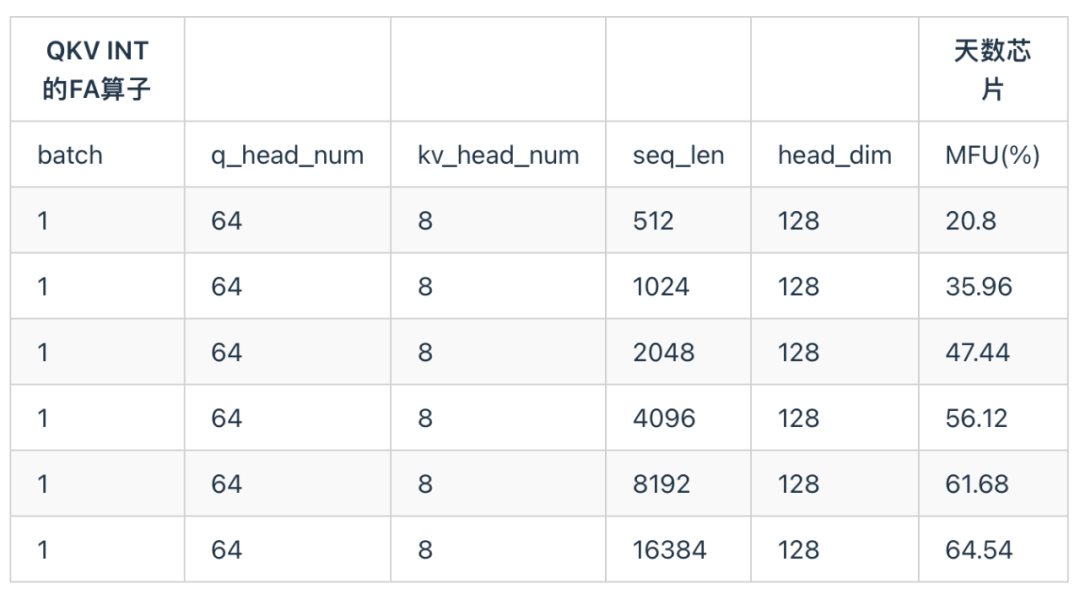
3.6.3 FA流水线分析图
为了进一步研究FA算子的效率,下面给出天数芯片的FA极致优化的流水图。如下图所示,可以看出流水线排布非常紧凑,资源空闲非常低,因此其FA算子效率较高。

4. 集合通信和通算融合分析
4.1 单机拓扑
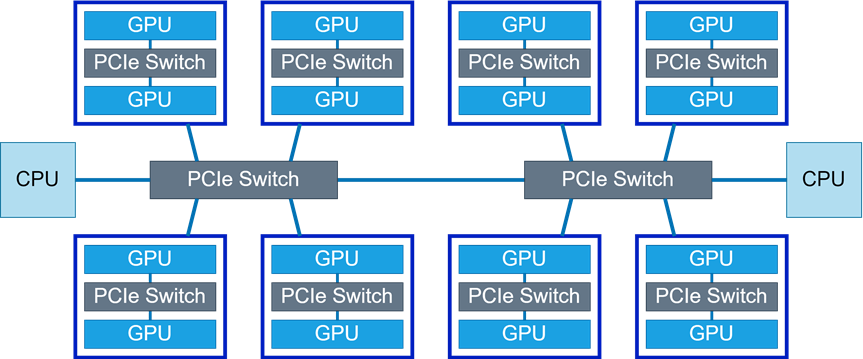
上图为天数芯片的16卡互联拓扑图。每两张卡之间通过一个PCIe 4.0 Switch连接,每4张卡之间通过一个PCIe 4.0 Switch连接,两个PCIe Switch连接到两个CPU上。对于All-Gather调用,执行Ring算法,经过15次环形传输,每个GPU上都有了完整的副本。对于All-Reduce调用,则使用Reduce-Scatter + All-Gather算法,执行两遍Ring算法,每一遍算法同样迭代15次。
4.2 All-Reduce通信
我们采用ByteMLPerf框架测试2卡间不同通信量下的通信延迟和算法带宽。天数芯片采用PCIe 4.0通信,理论上限为单向32GB/s,双向64GB/s。
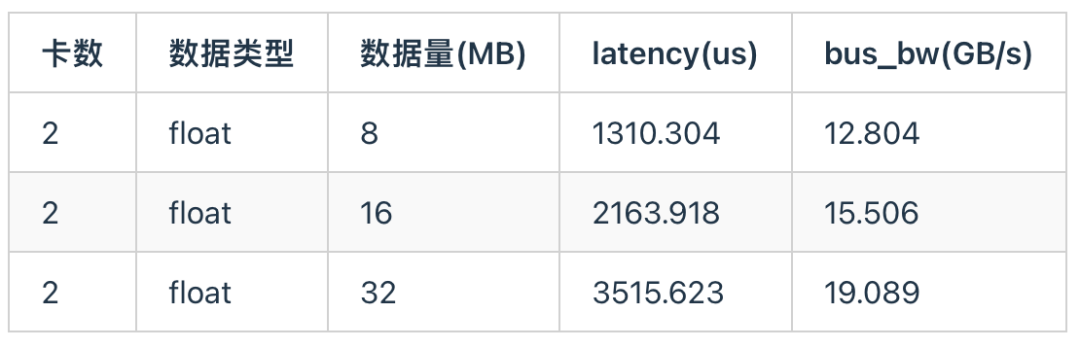
All-Reduce 使用 Ring 算法,对于双卡Reduce该算法包含三个核心步骤:
- 数据传输:将当前的 Rank 的数据发送到下一个 Rank 中;
- Barrier:在 Rank 发送数据完成后,会在 Rank 间进行一次 Barrier,用于确保数据传输完成;
- Reduce:将接收的数据和Rank 上的本地数据进行 Reduce。
再加上存在一定的PCIe协议开销和通信启动开销等,在16M长度下,all-reduce能达到约60%的带宽利用率。
4.3 All-Gather通信
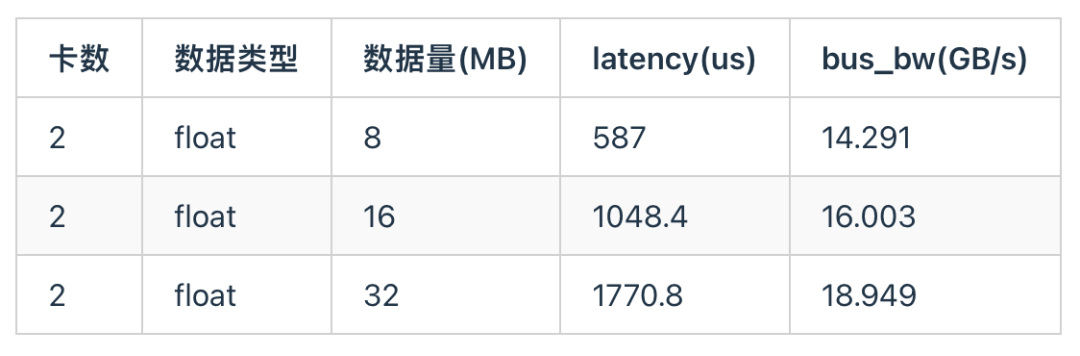
All-Gather 的算法与 All-Reduce 类似,区别在于不需要 Reduce。在16M长度下,all-gather同样能达到约60%的带宽利用率。
4.4 通算融合
天数针对大模型(LLM)中常见的GEMM + All Reduce流程进行了通算融合优化。得益于高度灵活的兼容CUDA架构,用户能够轻松进行计算/通信的细粒度控制,从而提高芯片的利用率。
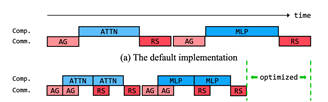
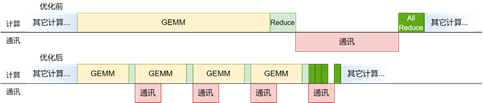
如上图所示,经过优化,计算和通讯阶段都被拆成了多份,因此不需要等到所有计算完成再开始通讯。经过合理的调度,通讯时间几乎完全隐藏在了GEMM和Reduce计算过程中,这使得天数芯片能够充分利用有限的互联带宽达到极高的Prefill效率。
5. 模型实测分析
5.1 理论分析 (TP v.s. PP)
由于天数芯片的算力密度较高,因此更适用于计算密集型的 prefill 场景,而对于访存密集型的 decode 场景则相对不占优势。
该芯片采用PCIe-Switch进行卡间互联,缺乏专门的高速互联总线,互联能力为64GB/s双向带宽,显著低于A800的400GB/s带宽。因此,在多卡并行时需要选择带宽需求更低的并行策略以避免性能瓶颈。尽管互联带宽更低,但就像3.2节里面说的那样,软件架构上的优化可以缩小硬件带来的差距,合理的软件设计与调度策略才是性能发挥的关键。
以Deepseek R1模型为例,权重使用int4存储时,可以在16张天数芯片上部署。假设序列长度4096,模型维度为7168,每张卡激活参数量2.3 B,模型有61层。当attn部分使用TP,ffn部分使用TP/EP时,每层共需要2次all-reduce通信操作。当通信数据类型为BF16时,在TP16时,每张卡的通信量为:

而对应的计算量为:
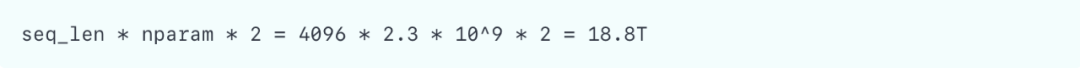
虽然实际执行过程中部分算子为memory-bound(执行时间会比纯计算长),同时可以结合使用通算融合优化,可以把该比例进行提高,通信所占时间仍较大。因此在天数芯片中TP使用较少,PP使用较多。
考虑仅使用PP并行时,当PP=16,每张卡的通信量为:
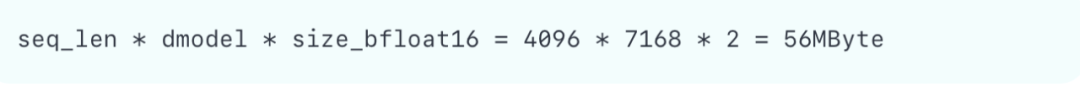
可见PP的通信开销远小于TP。
相比于TP并行策略,PP和CPP并行策略只有点对点通信,由上述计算可知其通信的理论耗时不到计算时间的1%,因此目前天数芯片适合低带宽需求的PP和CPP场景。下图是该芯片在一些常见尺寸下的P2P性能。
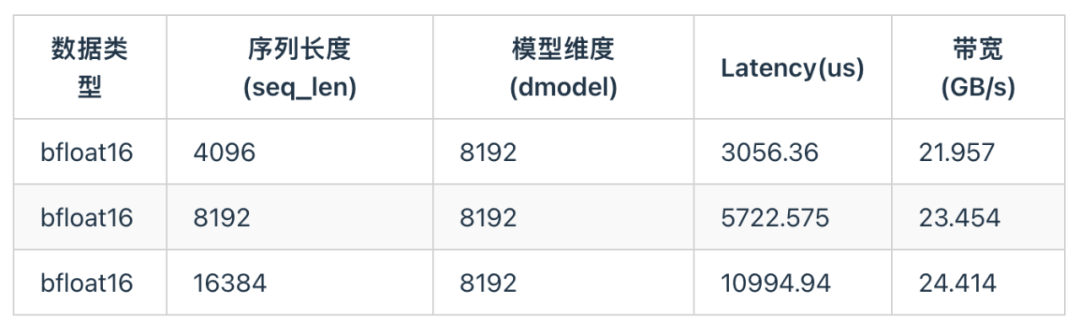
在几种序列长度下,P2P性能能够达到峰值的65%~75%,能够满足PP并行的要求。因此天数芯片主要使用PP并行时,可以忽略其通信时间。
目前天数芯片采用PCIe 4.0互联方案,若想支持更大TP并行,需要将计算/通信时间比进一步提高。因此在后续芯片设计中拟将互联方案升级到PCIe 5.0使得带宽翻倍。这样的话在算力不变的情况下,TP理论计算/通信时间比会同步翻倍。同时由于即使使用PCIe5.0,纯TP理论计算/通信时间仅能从0.5提升到1,计算占比仍较小,所以PP仍然需要,所以下一代芯片设计中将更好的支持P2P通信语义以更好地支持PP和CPP并行模式。
下面用vLLM框架测试了天数芯片和A800在两个经典模型上的prefill性能。
5.2 LLaMA2 7B Prefill实测结果
下面测试了英伟达A800和天数芯片在LLaMA2 7B Prefill w8a8-int8 场景下,随着输入Token个数增大,TTFT和吞吐的实测结果
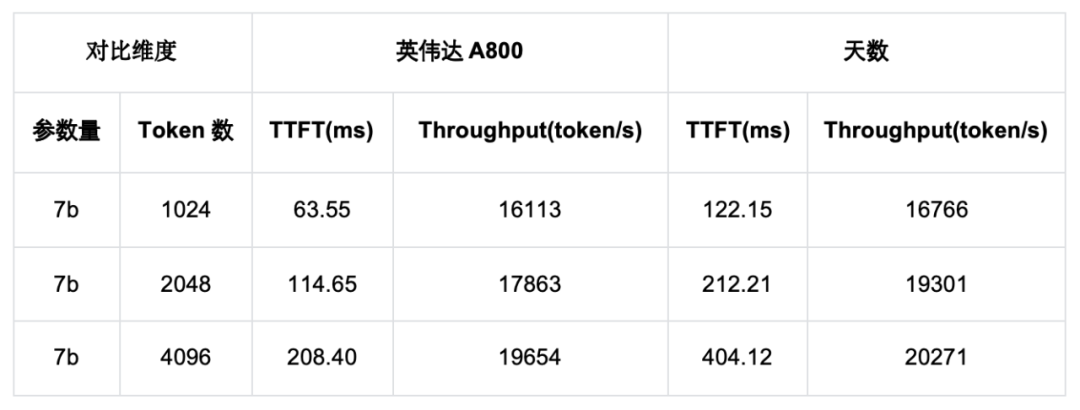
如上表所示,天数芯片的首词生成时间(TTFT)约为英伟达 A800 芯片的 2 倍;随着 Token 数的增加,该芯片吞吐性能相对于 A800 的优势逐步凸显,最终实测吞吐性能略优于英伟达 A800 芯片
5.3 DeepSeek R1 Prefill实测结果
下面测试了英伟达A800在DeepSeek R1 671B Prefill场景下,随着输入Token个数增大,TTFT和吞吐的实测结果(注:vLLM在英伟达A800芯片上不支持MoE W8A8-int8,因此A800采用w4a16量化方案)。为了最大化吞吐量,同时统一测试标准,A800和天数芯片均采用TP2 PP8的并行方案。
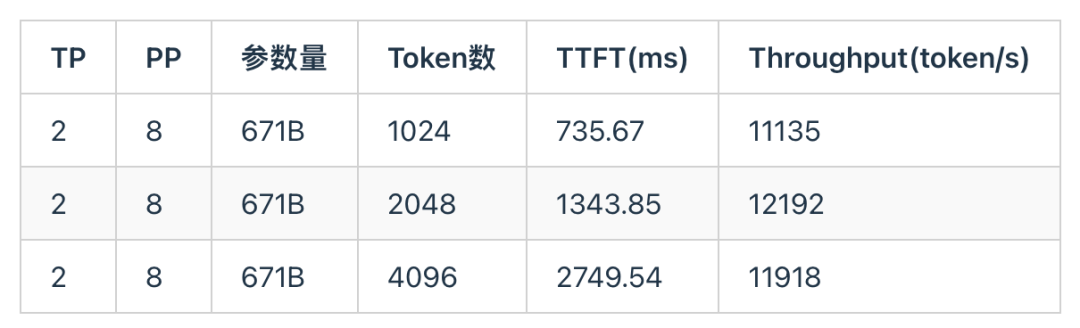
下面是天数芯片在DeepSeek R1 671B Prefill场景下,随着输入Token个数增大,TTFT和吞吐的实测结果。由于该芯片的互联带宽较低,因此采用较大的PP能够缓解通信的大小,充分发挥芯片的硬件资源,降低延迟,提高吞吐。
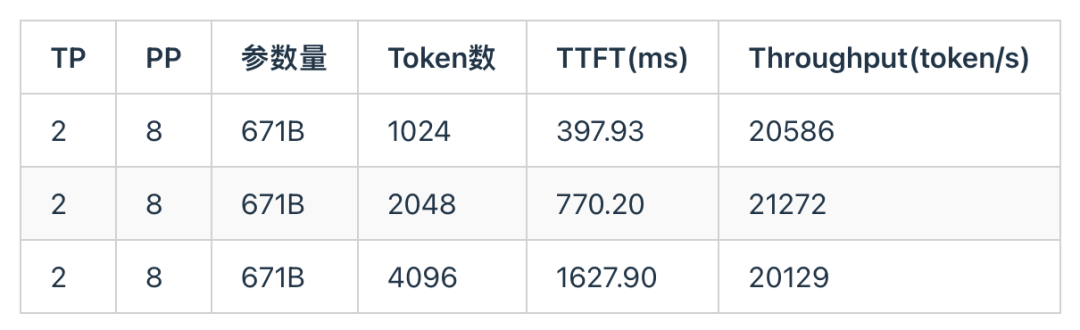
通过对比两组实测结果可以发现,得益于天数芯片针对 DeepSeek R1 模型的定制化适配与优化,其 TTFT 显著低于 NVIDIA A800,同时整体吞吐性能也优于 A800。需要指出的是,天数芯片对 DeepSeek 模型进行了 W4A8 量化优化,对应的计算精度为 INT8;而 A800 采用 W4A16 量化方案,对应精度为 BF1

